


Wireshark流量分析总结&合集
wireshark基础
Frame:物理层数据帧的情况;
Ethernet II:数据链路层以太网帧头部的信息;
Internet Protocol Version 4:网络层数据包头部信息;
Transmission Control Protocol:传输层的数据段头部信息。
Time时间分析
Frame
frame.time
frame.time 字段(Absolute time when this frame was captured)表示捕获该数据包的时间戳。它显示了数据包在网络中被抓取到的精确时间,包括日期、小时、分钟、秒、毫秒、微秒甚至纳秒数(依赖于捕获文件实际可用的时间戳精度)。
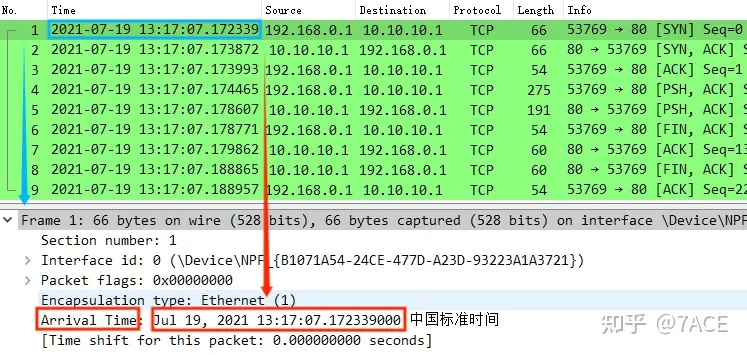
Packet List 中的 Time 格式,可在 View - Time Display Format 中更改,包括各类时间格式和时间精度。
frame.time_delta
frame.time_delta 字段(Time delta from previous captured frame)表示该数据包相对于前一个数据包捕获时间的差值。换句话说,它表示该数据包及前一个数据包之间的时间间隔。
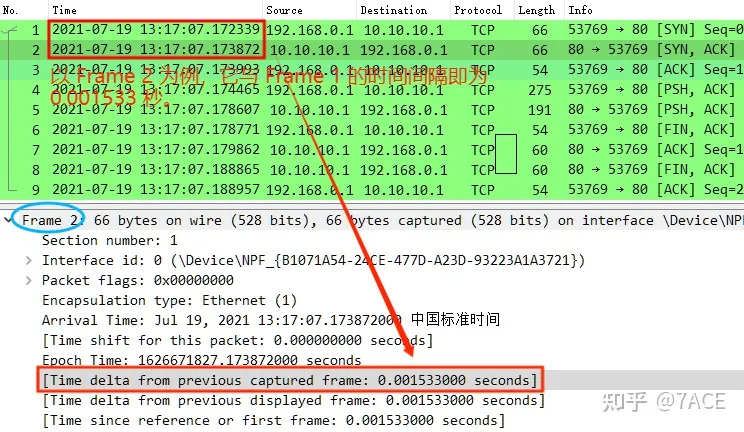
frame.time_delta_displayed
frame.time_delta_displayed 字段(Time delta from previous displayed frame)与 frame.time_delta 字段的含义类似,也是表示当前数据包和前一个数据包之间的时间间隔。但两者有一个重要区别:frame.time_delta_displayed 字段只计算显示到界面的每个数据包之间的时间间隔,也就是说,如果 Wireshark 应用了显示过滤而没有显示某些数据包,那么这些数据包相对于前后数据包的时间差值将不会计算在内。
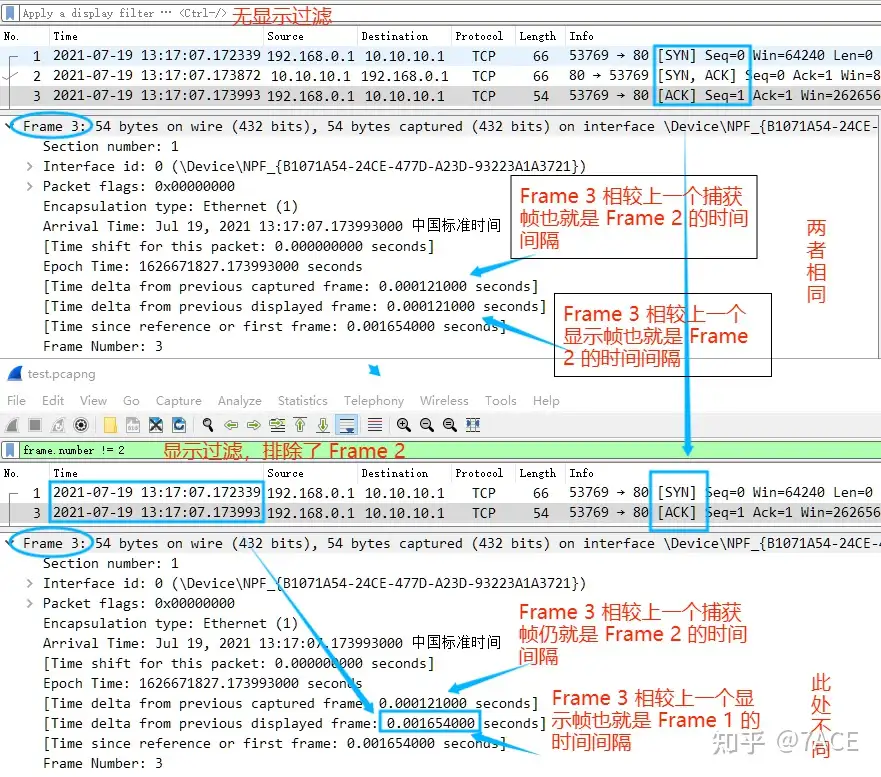
因为在网络数据包分析中,更多的情况会应用各种显示过滤,所以 frame.time_delta_displayed 字段相对于 frame.time_delta 字段会更有用,可以提供更准确的时间间隔。
frame.time_relative
frame.time_relative 字段(Time relative to time reference or first frame)是指当前数据包的捕获时间和首个数据包的捕获时间的时间差。frame.time_relative 可以在时间轴上用来更好地理解数据包的相对时间,可以快速判断在不同数据包之间的时间间隔。

该字段通常配合 Time Reference 功能一起使用,通过 Time Reference 功能可设置任意数据包作为参考时间值。譬如想知道 TCP 四次挥手的第三次 FIN 与第一次 FIN 之间的时间间隔,就可以将 Frame 6 设置成参考,也就是对后面的数据包来说,Frame 6 即为第一个数据帧,那么 Frame 8 中的 frame.time_relative 字段值即为 Frame 8 与 Frame 6 的时间间隔
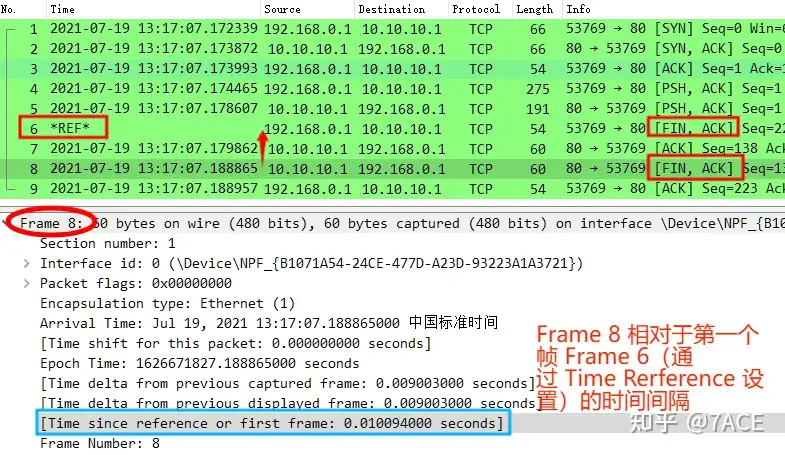
Time Reference,可设置多个数据帧作为不同的参考,也可随时取消设置。
TCP
tcp.time_delta
tcp.time_delta 字段(Time delta from previous frame in this TCP stream)表示当前 TCP 数据包和同一条 TCP 流中前一个 TCP 数据包之间的时间差。如字面意思,这个字段只能在 TCP 协议中使用,并且只记录同一条 TCP 流的数据包,即源和目的 IP 、端口相同,协议为 TCP 的数据包。

tcp.time_delta 可以用来检测 TCP 连接延迟、流量控制、拥塞控制情况等。例如,如果某些数据包之间的时间差值非常大,那么可能表明数据传输过程中存在阻塞或者其他性能问题,如下显示过滤大于等于 180ms 间隔的 TCP 数据包。
tcp.time_delta >= 0.180
tcp.time_relative
tcp.time_relative 字段(Time relative to first frame in this TCP stream)表示当前 TCP 数据包相对于同一条 TCP 流中第一个 TCP 数据包之间的时间差。如字面意思,这个字段也只能在 TCP 协议中使用,并且只记录同一条 TCP 流的数据包,即源和目的 IP 、端口相同,协议为 TCP 的数据包。
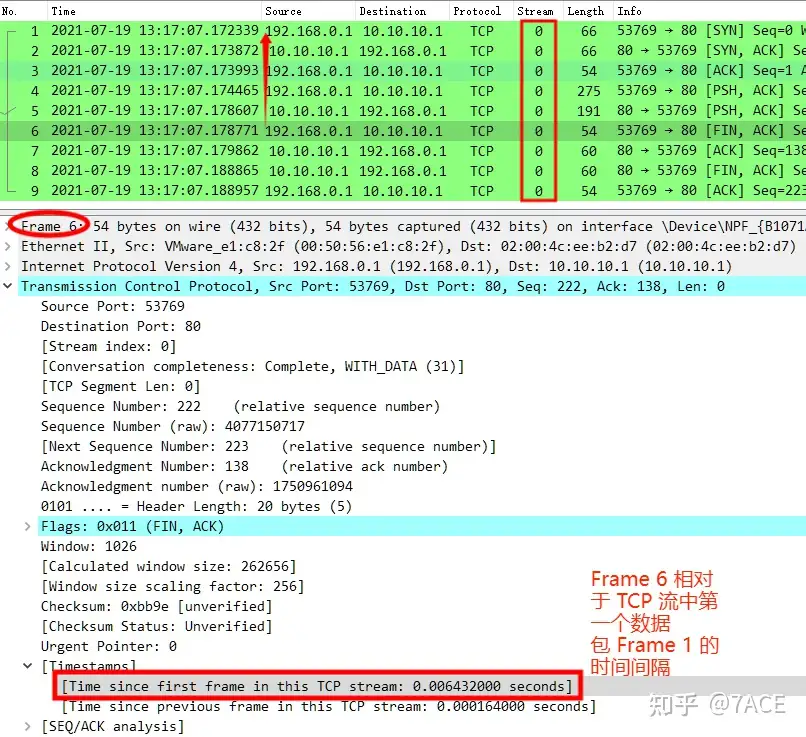
tcp.analysis.initial_rtt
tcp.analysis.initial_rtt 字段(How long it took for the SYN to ACK handshake)是指 TCP 三次握手建立的时间间隔,是用来测量 TCP 连接的延迟时间的一个指标。IRTT 表示“初始往返时间”(Initial Round Trip Time),在 TCP 连接刚开始建立的时候,计算 IRTT 就非常重要了,可以作为该条 TCP 流判断后续 TCP 数据包交互 RTT 时间、TCP 传输延迟等情况的一个参考基准。
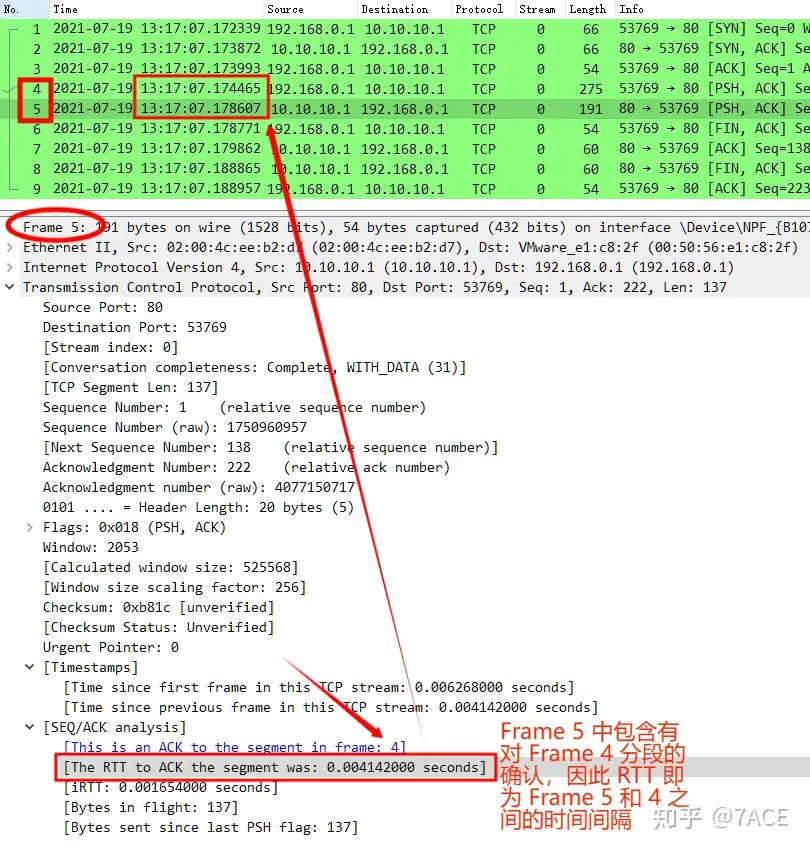
tcp.analysis.ack_rtt
tcp.analysis.ack_rtt 字段(How long time it took to ACK the segment)是指 TCP 数据包分段和该 TCP 数据包分段的 ACK 确认之间的时间间隔,是用来测量 TCP 连接的延迟时间的一个指标。
HTTP
http.time
http.time 是 HTTP 协议中的时间字段(Time since the request was sent),表示 HTTP 请求到响应的时间间隔。更具体地说,它是 HTTP 请求的时间戳,到 HTTP响应的时间戳之间的时间差。
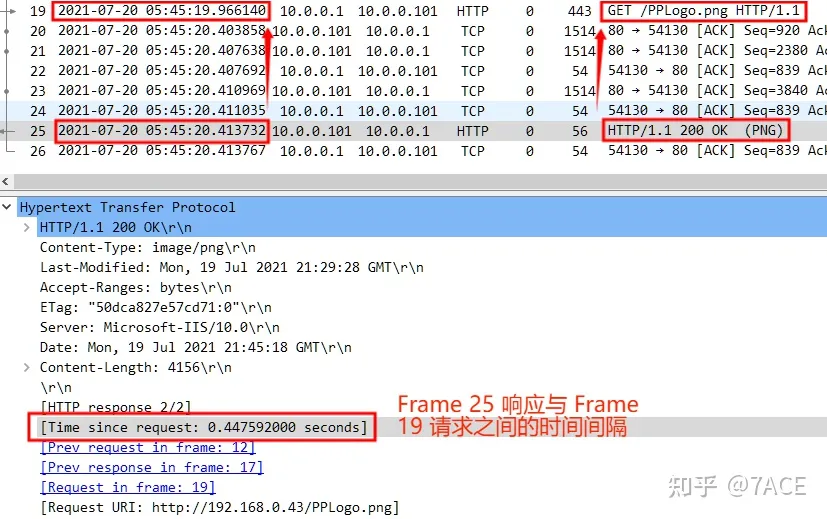
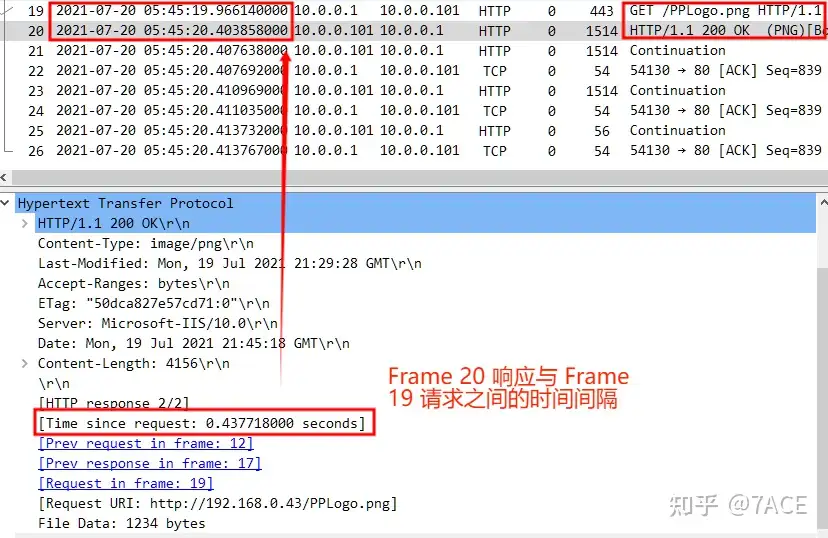
需要注意的是,默认情况下的 Wireshark 对于 HTTP 请求和响应的解析有着不一样的定义,在上图 HTTP 响应(譬如 200 OK),是在包括响应数据全部传输完后的最后一个数据包中定义,这样 http.time 值会相对偏大。而我们日常理解的 HTTP ,响应一般是紧跟请求之后出现的,这样就需要更改 Wireshark 中 TCP 设置,将 Allow subdissector to reassemble TCP streams 选项去除勾选,这样真正的 http.time 就会如下图所示,更容易理解,而值会相对偏小。
DNS
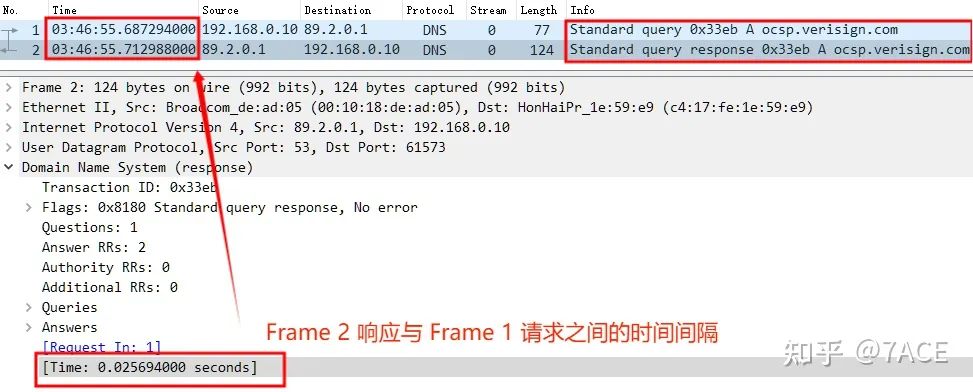
dns.time
dns.time 是DNS 协议数据包中的时间字段(The time between the Query and the Response),表示 DNS 查询请求到响应的时间间隔。具体而言,它是 DNS 查询请求的时间戳,到 DNS 响应的时间戳之间的时间差。
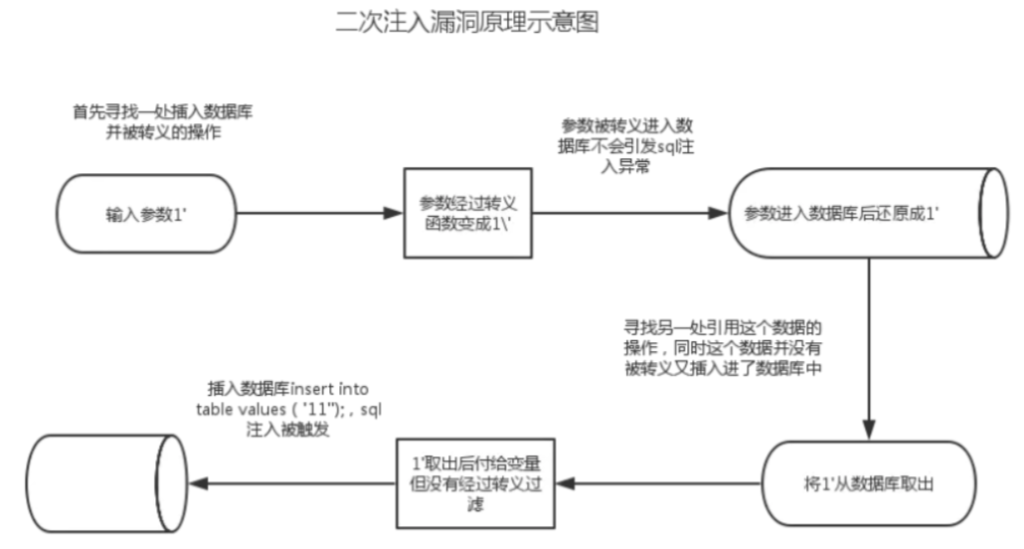
攻防世界-流量分析1
筛选http流量,可以看到有大量请求,解析其中一个请求
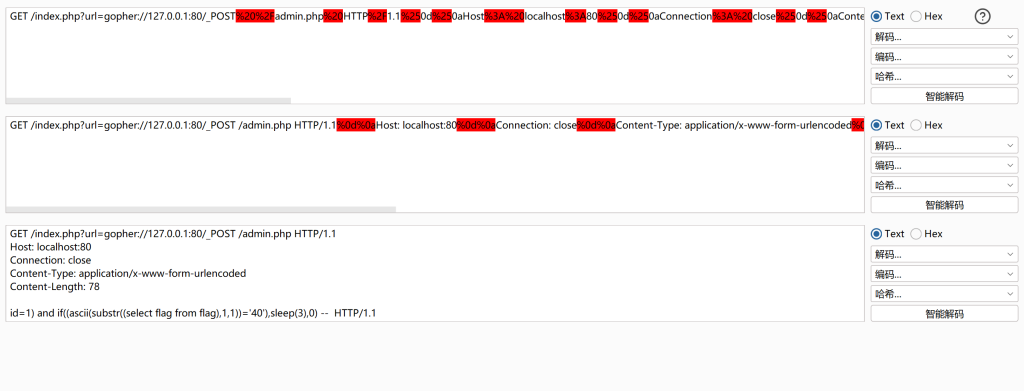
可以看到是时间盲注,若成功,则延迟3S
输入规则筛选
http.time>=3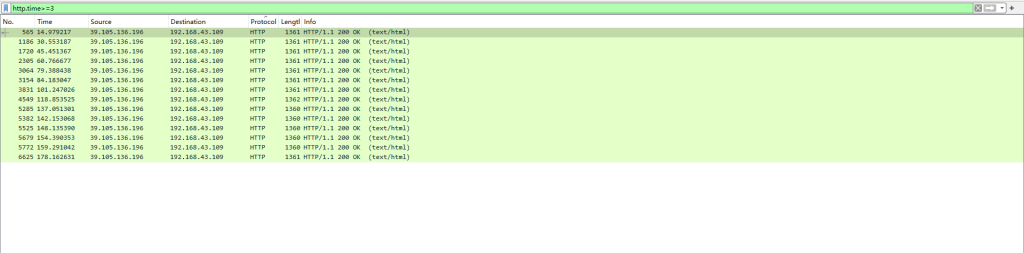
依次解码得到ascii码
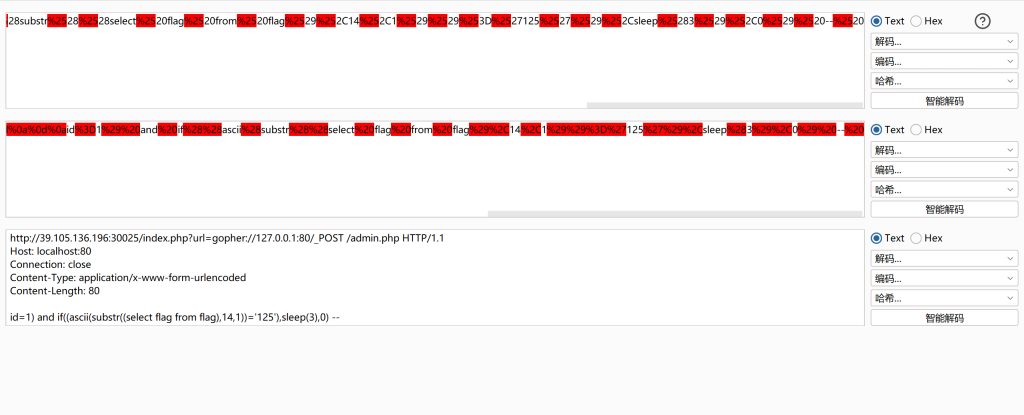
使用脚本转为字符
# 假设你的文件名为 numbers.txt
file_name = 'numbers.txt'
try:
# 打开文件
with open(file_name, 'r') as file:
# 初始化一个空字符串来保存所有的 ASCII 字符
ascii_string = ''
# 逐行读取
for line in file:
# 尝试将行内容转换为整数
try:
number = int(line.strip())
# 检查数字是否在有效的 ASCII 范围内
if 0 <= number < 128:
# 转换为 ASCII 字符
ascii_character = chr(number)
# 将字符添加到字符串中
ascii_string += ascii_character
else:
print(f"The number {number} is not in the valid ASCII range.")
except ValueError:
print(f"The line '{line.strip()}' is not a valid integer.")
# 打印整个转换后的 ASCII 字符串
print("The full ASCII string is:")
print(ascii_string)
except FileNotFoundError:
print(f"The file {file_name} was not found.")
except Exception as e:
print(f"An error occurred: {e}")
flag{1qwy2781}
攻防世界 流量分析
打开wireshark分析流量,发现大量请求,找到http请求,发现是sql盲注。
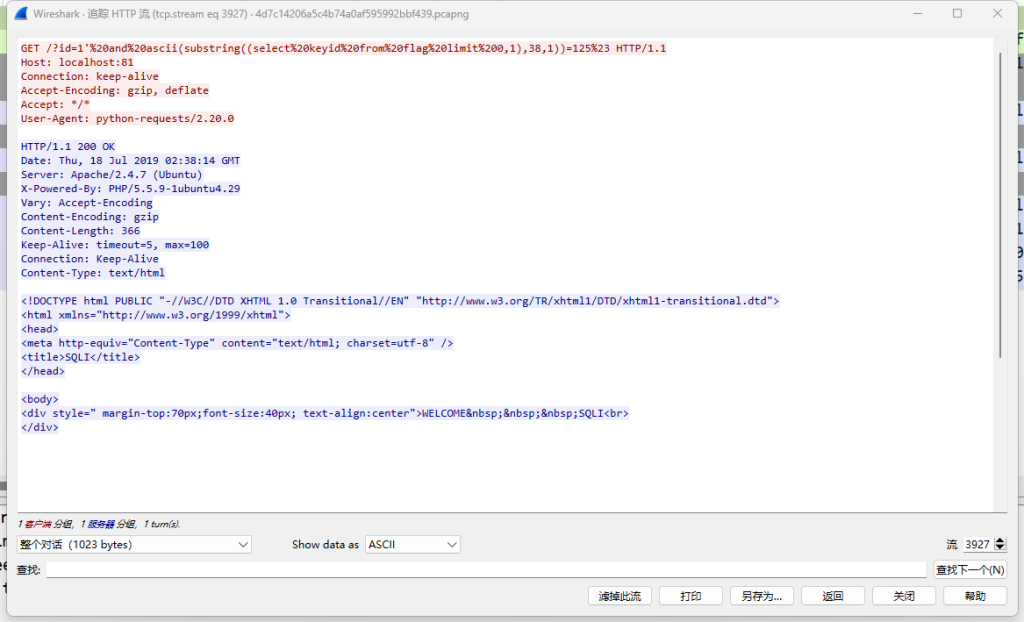
分析可知Length长度为695的为盲注正确的请求,注入成功的页面会显示welcome to sanya
输入过滤条件
http.content_length==336
导出分组解析结果,as Json
使用python脚本读取并解析json文件,获取asscii码,并转为字母
import json
import re
import urllib.parse
def read_json():
with open('1.json', encoding="utf-8") as f:
data = json.load(f)
for i in range(len(data)):
url = urllib.parse.unquote(data[i]["_source"]["layers"]["http"]["http.response_for.uri"])
pattern = r'(\d{2,3})#'
ascii_num = re.search(pattern, url).group(1)
print(ascii_num)
if __name__ == '__main__':
read_json()flag{c2bbf9cecdaf656cf524d014c5bf046c}
参考资料

空空如也!