


基于pytorch的Mnist手写体识别
构建自己的数据读写类
自定义的数据读写类要基于Dataset类构建,并实现其中的三个方法。Dataset类位于torch.utils.data
def __init__() # 用来初始化
def __getitem__() #用来获取初始化后的每一个数据,接收值是一个索引,应该返回(data,label)
def __len__() # 获取数据集的大小构建完成后可以使用类似于数组的方式访问,如MyDataset[0]
代码如下:
class MnistDataSet(Dataset):
def __init__(self, file_path, is_train=True):
# 使用scipy读入mat文件数据
mnist_all = sio.loadmat(file_path)
train_raw = []
test_raw = []
# 依次读入数据集0-9
for i in range(10):
train_temp = mnist_all["train" + str(i)]
for j in train_temp:
j = np.array(j) / 225.0
train_raw.append([j, i])
for i in range(10):
test_temp = mnist_all["test" + str(i)]
for j in test_temp:
j = np.array(j) / 225.0
test_raw.append([j, i])
self.trainDataSet = train_raw
self.testDataSet = test_raw
self.is_train = is_train
def __getitem__(self, index):
if self.is_train:
dataSet = self.trainDataSet
else:
dataSet = self.testDataSet
img = dataSet[index][0]
labelArr = np.eye(10)
label = labelArr[dataSet[index][1]]
return img, label
def __len__(self):
if self.is_train:
return len(self.trainDataSet)
else:
return len(self.testDataSet)接下来使用迭代器加载数据集,如下。
DataLoader位于torch.utils.data.dataloader
# 读取数据
trainSet = MnistDataSet(file_path="./data/mnist_all.mat", is_train=True)
trainDataLoader = DataLoader(trainSet, batch_size=batch_size, shuffle=True)构建网络
网络结构为(卷积层+池化层+激活层)X2+(全连接层+激活层)X3
损失函数为交叉熵损失函数。
代码如下:
class CnnNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, (3, 3), (1, 1))
self.conv2 = nn.Conv2d(32, 64, (3, 3), (1, 1))
self.mp = nn.MaxPool2d(kernel_size=(2, 2), stride=2)
self.fc1 = nn.Linear(1600, 1024)
self.fc2 = nn.Linear(1024, 1024)
self.fc3 = nn.Linear(1024, 128)
self.fc4 = nn.Linear(128, 10)
self.relu = nn.ReLU()
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = x.reshape(-1, 1, 28, 28)
y = self.conv1(x)
y = self.relu(y)
y = self.mp(y)
y = self.conv2(y)
y = self.relu(y)
y = self.mp(y)
y = y.reshape(-1, 1600)
y = self.relu(self.fc1(y))
y = self.relu(self.fc2(y))
y = self.relu(self.fc3(y))
y = self.fc4(y)
y = self.softmax(y)
return y训练过程
def train(epoch, device, batch_size, lr, save_path):
model = CnnNet()
model.train()
# 读取数据
trainSet = MnistDataSet(file_path="./data/mnist_all.mat", is_train=True)
trainDataLoader = DataLoader(trainSet, batch_size=batch_size, shuffle=True)
# 定义交叉熵损失
loss_func = torch.nn.CrossEntropyLoss()
# 定义Adam优化器
optimizer = optim.Adam(model.parameters(), lr=lr)
for e in range(epoch):
for i, (data, target) in enumerate(trainDataLoader):
data, target = data.to(device).float(), target.to(device)
out = model(data)
p = torch.argmax(out, dim=1)
y = torch.argmax(target, dim=1)
loss = loss_func(out, y)
# 梯度清零
optimizer.zero_grad()
loss.backward()
# 更新参数
optimizer.step()
if i % 100 == 0:
# 准确率计算
train_correct = (p == y).sum() / batch_size
print("Epoch为" + str(e))
print("第" + str(e * len(trainDataLoader) + i) + "次训练损失为" + str(loss))
print("第" + str(e * len(trainDataLoader) + i) + "正确率为" + str(train_correct))
# 模型保存
torch.save(model, save_path)验证过程
def dev(device, batch_size, model_path):
model = torch.load(model_path)
trainSet = MnistDataSet(file_path="./data/mnist_all.mat", is_train=False)
trainDataLoader = DataLoader(trainSet, batch_size=batch_size, shuffle=False)
train_correct = 0
for i, (data, target) in enumerate(trainDataLoader):
data, target = data.to(device).float(), target.to(device)
out = model(data)
p = torch.argmax(out, dim=1)
y = torch.argmax(target, dim=1)
train_correct += (p == y).sum()
print("验证集正确率为" + str(train_correct / (len(trainDataLoader) * batch_size)))运行
if __name__ == '__main__':
epoch = 15
batch_size = 128
lr = 0.001
device = torch.device("cpu")
train(epoch, device, batch_size, lr, save_path="model2.pkl")
dev("cpu", 1024, "model2.pkl")结果:
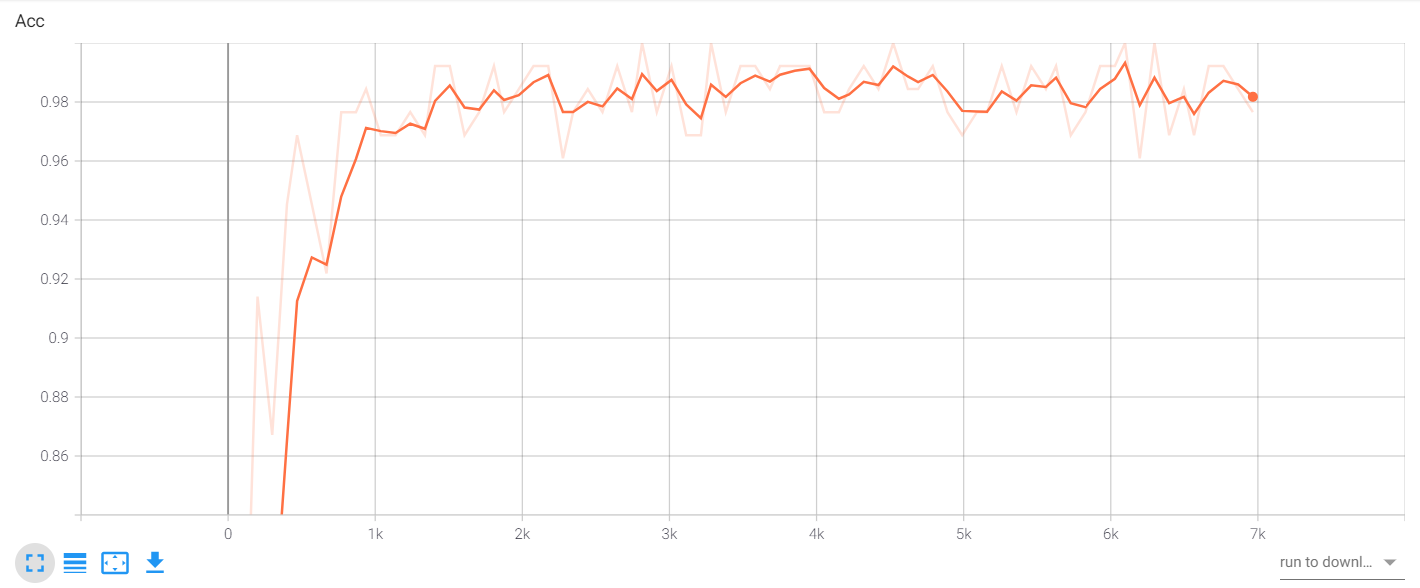
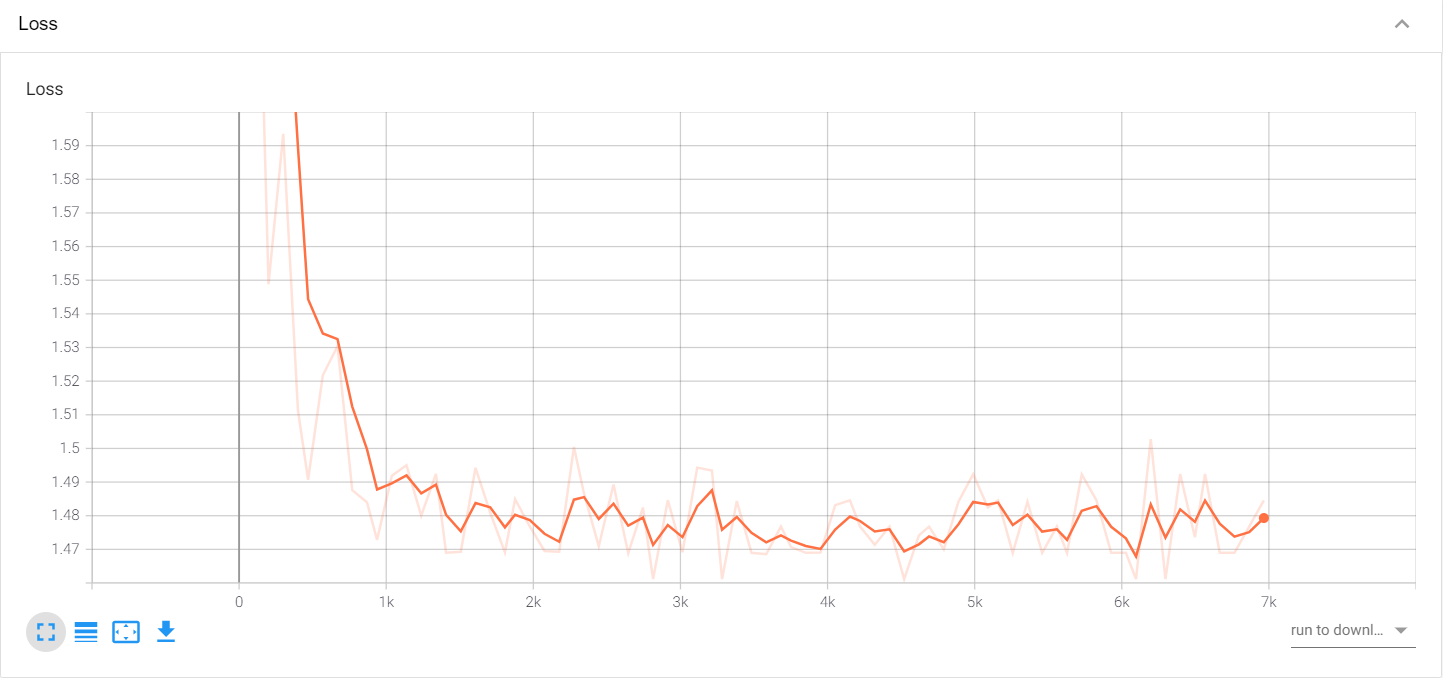
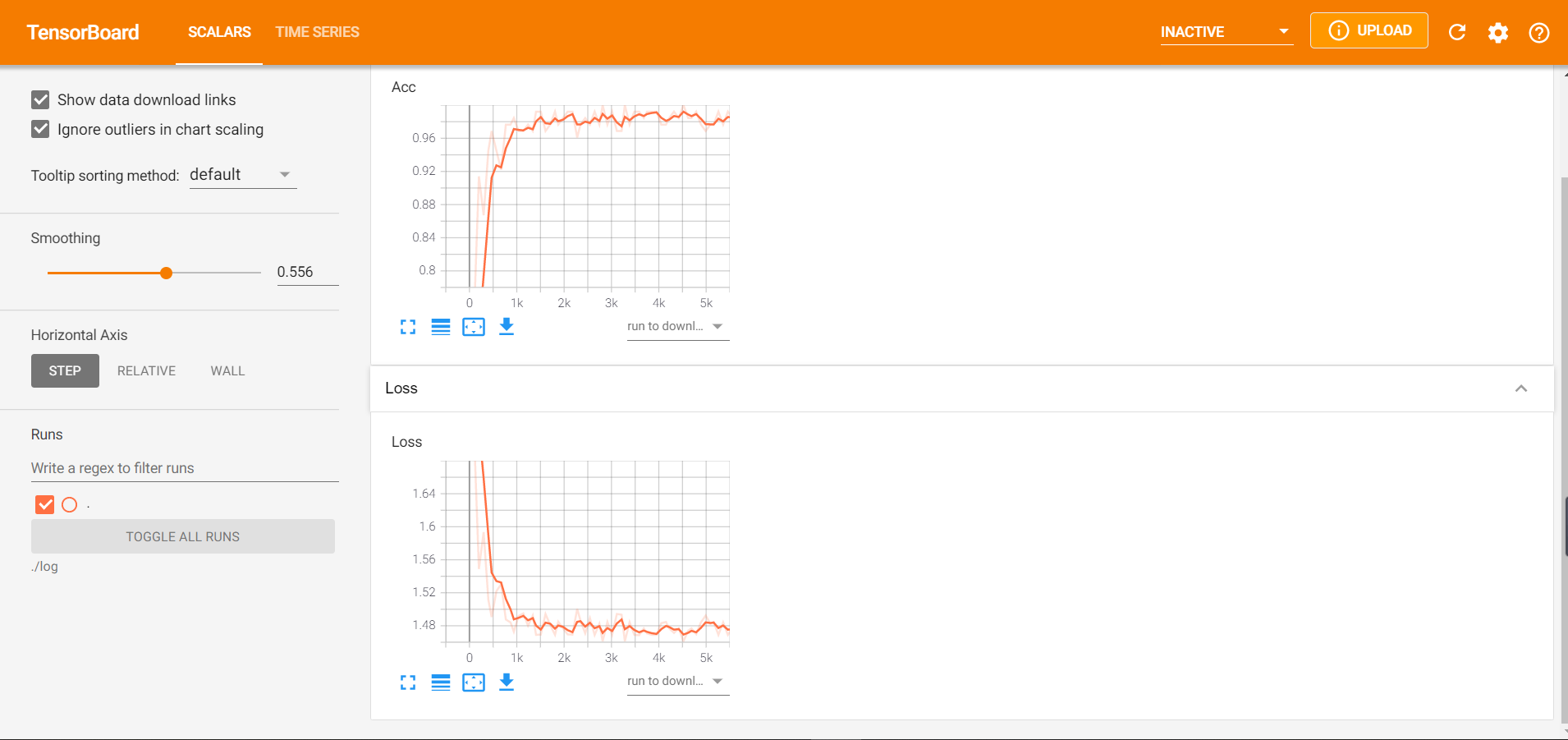
验证集正确率为:0.9612
TensorBoard 可视化
writer = SummaryWriter('./log') # 用于指定log保存位置,后续可视化的数据来源
writer.add_scalar("Loss", loss, e * len(trainDataLoader) + i) # 绘制曲线图add_scalar的参数如下:
- tag (string):数据标识符
- scalar_value (float or string/blobname):要保存的数值
- global_step (int):全局步值
- walltime (float):可选参数,用于记录发生的时间,默认为 time.time()
启动可视化网页:
--logdir 保存的文件夹位置
--port 端口号
tensorboard --logdir ./log --port 9000所有代码
这次不传Github了,所有的代码都在这里。
import torch
import numpy as np
import scipy.io as sio
import torch.nn as nn
from torch import optim
from torch.utils.data import Dataset
from torch.utils.data.dataloader import DataLoader
from torch.utils.tensorboard import SummaryWriter
class MnistDataSet(Dataset):
def __init__(self, file_path, is_train=True):
# 使用scipy读入mat文件数据
mnist_all = sio.loadmat(file_path)
train_raw = []
test_raw = []
# 依次读入数据集0-9
for i in range(10):
train_temp = mnist_all["train" + str(i)]
for j in train_temp:
j = np.array(j) / 225.0
train_raw.append([j, i])
for i in range(10):
test_temp = mnist_all["test" + str(i)]
for j in test_temp:
j = np.array(j) / 225.0
test_raw.append([j, i])
self.trainDataSet = train_raw
self.testDataSet = test_raw
self.is_train = is_train
def __getitem__(self, index):
if self.is_train:
dataSet = self.trainDataSet
else:
dataSet = self.testDataSet
img = dataSet[index][0]
labelArr = np.eye(10)
label = labelArr[dataSet[index][1]]
return img, label
def __len__(self):
if self.is_train:
return len(self.trainDataSet)
else:
return len(self.testDataSet)
class CnnNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, (3, 3), (1, 1))
self.conv2 = nn.Conv2d(32, 64, (3, 3), (1, 1))
self.mp = nn.MaxPool2d(kernel_size=(2, 2), stride=2)
self.fc1 = nn.Linear(1600, 1024)
self.fc2 = nn.Linear(1024, 1024)
self.fc3 = nn.Linear(1024, 128)
self.fc4 = nn.Linear(128, 10)
self.relu = nn.ReLU()
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = x.reshape(-1, 1, 28, 28)
y = self.conv1(x)
y = self.relu(y)
y = self.mp(y)
y = self.conv2(y)
y = self.relu(y)
y = self.mp(y)
y = y.reshape(-1, 1600)
y = self.relu(self.fc1(y))
y = self.relu(self.fc2(y))
y = self.relu(self.fc3(y))
y = self.fc4(y)
y = self.softmax(y)
return y
def train(epoch, device, batch_size, lr, save_path):
model = CnnNet()
model.train()
# 读取数据
trainSet = MnistDataSet(file_path="./data/mnist_all.mat", is_train=True)
trainDataLoader = DataLoader(trainSet, batch_size=batch_size, shuffle=True)
writer = SummaryWriter('./log')
# 定义交叉熵损失
loss_func = torch.nn.CrossEntropyLoss()
# 定义Adam优化器
optimizer = optim.Adam(model.parameters(), lr=lr)
for e in range(epoch):
for i, (data, target) in enumerate(trainDataLoader):
data, target = data.to(device).float(), target.to(device)
out = model(data)
p = torch.argmax(out, dim=1)
y = torch.argmax(target, dim=1)
loss = loss_func(out, y)
# 梯度清零
optimizer.zero_grad()
loss.backward()
# 更新参数
optimizer.step()
if i % 100 == 0:
# 准确率计算
train_correct = (p == y).sum() / batch_size
print("Epoch为" + str(e))
print("第" + str(e * len(trainDataLoader) + i) + "次训练损失为" + str(loss))
writer.add_scalar("Loss", loss, e * len(trainDataLoader) + i)
print("第" + str(e * len(trainDataLoader) + i) + "正确率为" + str(train_correct))
writer.add_scalar("Acc", train_correct, e * len(trainDataLoader) + i)
# 模型保存
torch.save(model, save_path)
def dev(device, batch_size, model_path):
model = torch.load(model_path)
trainSet = MnistDataSet(file_path="./data/mnist_all.mat", is_train=False)
trainDataLoader = DataLoader(trainSet, batch_size=batch_size, shuffle=False)
train_correct = 0
for i, (data, target) in enumerate(trainDataLoader):
data, target = data.to(device).float(), target.to(device)
out = model(data)
p = torch.argmax(out, dim=1)
y = torch.argmax(target, dim=1)
train_correct += (p == y).sum()
print("验证集正确率为" + str(train_correct / (len(trainDataLoader) * batch_size)))
if __name__ == '__main__':
epoch = 15
batch_size = 128
lr = 0.001
device = torch.device("cpu")
train(epoch, device, batch_size, lr, save_path="model2.pkl")
dev("cpu", 1024, "model2.pkl")

空空如也!